BLOG09b: CPU & Memory Metrics — The Real Heartbeat of HPA
BLOG23: CPU & Memory Metrics — The Real Heartbeat of HPA
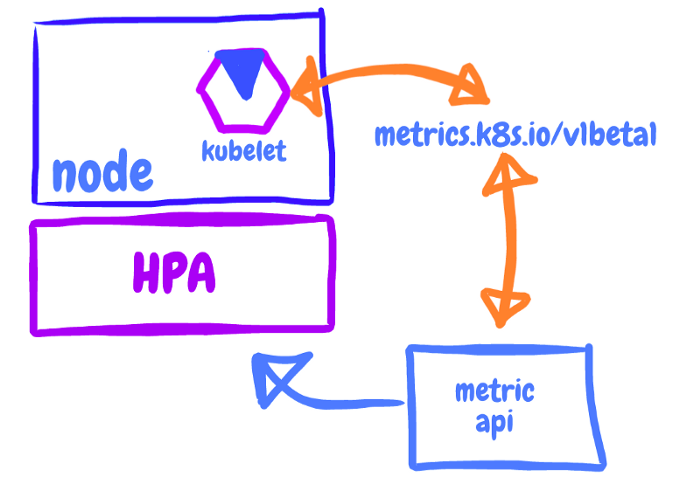
1. CPU & Memory Metrics — The Real Heartbeat of HPA
CPU — the millicore universe
⚡ Why millicores?
CPU Utilization Formula (absolutely key!)
2. Memory — the MiB universe
Memory is not compressible, unlike CPU.
Memory autoscaling is rare
3. HPA Cooldown Period — the “patience timer”
A. Stabilization Window (default 300s for scale-down only)
You can customize it:
B. Scale-Up "Forgetting Window" (default 15 seconds)
C. Kubelet Metrics Delay (~15s → 30s)
4. Why HPA scaling works best with CPU & not memory
CPU scaling signals:
Memory:
5. The "Moving Average" Mental Model (How HPA thinks)
6. Your Prime App Autoscaling Example
PreviousBLOG09a: Tiny Toy Application—A Pocket-Sized Traffic BoothNextBLOG09c: Prometheus Metric Collection Flow
Last updated